Pythonの起動時のメモリ消費を何とかしたかった
始めに
※ 結果的に言えばどうにもできなかった話です。
検証環境へのデプロイが通常なら10分程度で終わるはずなのに、最悪のパターンだと30分くらいかかるようになりました。原因を追っていくと、どうやらFastAPIが起動時にメモリを大量消費していることがわかりました。特にライブラリのimport時に非常にメモリを消費しており、メモリ使用量が100%になって張り付いた結果、応答待ちになっていることがわかりました。取り急ぎ、検証環境のメモリを増やすことで通常通りの10分程度のデプロイ時間に戻せたのですが、通常利用時のメモリ使用量が多くないのに、起動時の問題だけでメモリを増やすのは根本解決にはならないと考えていたので、それを何とかしようとした試みについて書いたブログです。
環境
- Python
- 3.13
- tuna
- 0.5.11
実装
import時間を知りたい
まずは、import時間を可視化することを目指しました。import時間が長いモジュールはメモリ消費量が多い傾向があるためです。
Python 3.7以降であれば、標準機能としてimportにかかる時間を表示できる機能があります。 機能をオンにすると次のようにどのライブラリでimporttimeがかかっているか出力されます。
import time: self [us] | cumulative | imported package import time: 88 | 88 | django import time: 646 | 646 | billiard.reduction import time: 1221 | 1867 | billiard.connection import time: 662 | 2528 | billiard.dummy import time: 1798 | 4326 | billiard.pool import time: 111 | 111 | redis import time: 68 | 68 | uwsgi
起動オプションに-X importtimeを付与してください。または環境変数のPYTHONPROFILEIMPORTTIMEを設定してください。
# オプション python3 -X importtime -m uvicorn src.main:app --host 0.0.0.0 --port 9997 # 環境変数 PYTHONPROFILEIMPORTTIME=1 python3 -m uvicorn src.main:app --host 0.0.0.0 --port 9997
ただし、これだけ見ても理解が難しいので、別のツールで可視化します。ファイルとして出力しましょう。
python3 -X importtime -m uvicorn src.main:app --host 0.0.0.0 --port 9997 2>&1 | grep "^import time:" > importtime.log # `2>&1` 標準エラー出力を標準出力にリダイレクトします(importtimeの結果は標準エラーに出力されるため)
もし、Dockerで起動しているアプリケーションであれば、次のコマンドでログを取得しましょう。
# compose.yml に定義された fastapi サービスをログに出力する ## --no-log-prefix が付与されているとどのサービスから出力されたか、というログを削ります。この文言があると構造が変わるので可視化できません。 docker compose logs --no-log-prefix fastapi > importtime.log
import時間の可視化
今回、import時間の可視化にtunaを使用しました。使用方法は簡単で、先ほど出力したファイルを読み込ませるだけです。
uv add --dev tuna uv run tuna importtime.log
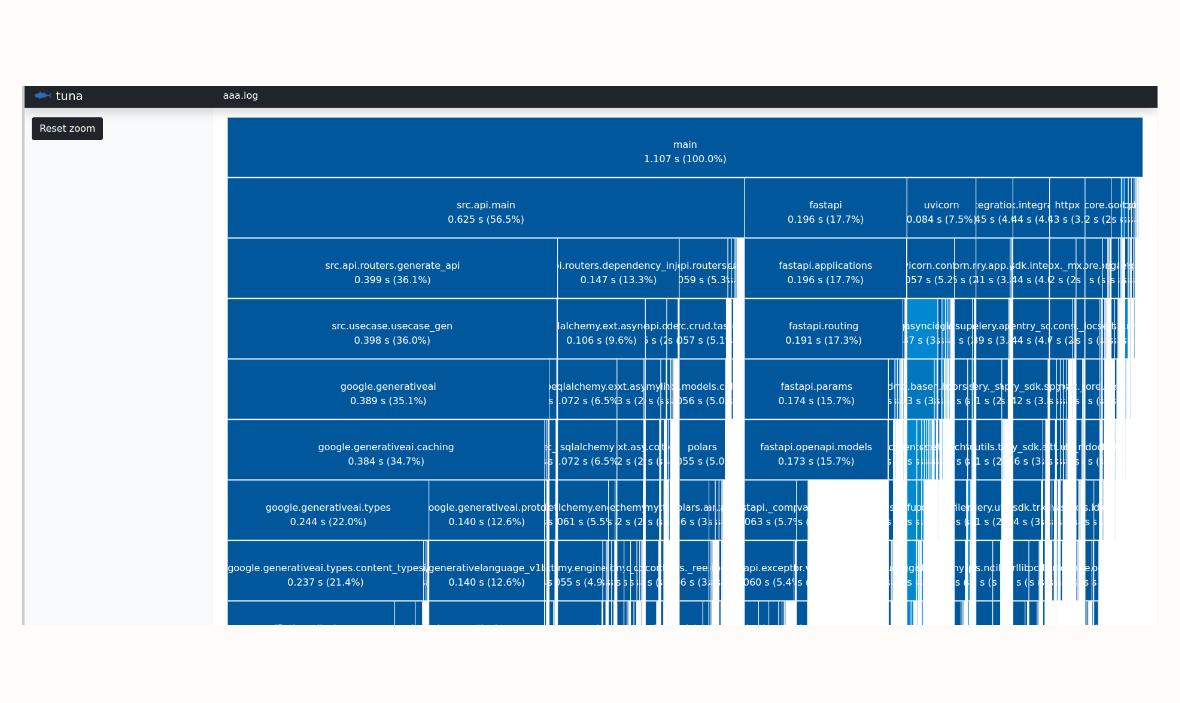
私のソースコードではsrc.api.mainに依存しているgoogle.generativeaiライブラリが重そうであることがわかりました。
なお、もし可視化できない場合、内部的に起動が終わっておらず、可視化に必要な情報がそろいきっていない場合があるので、起動を待ってから再度ファイルにしましょう。
対策しようとした方法
基本的にはlazy loadで対応することになります。もしくは、先に重たいライブラリを読み込んでおくことで、メモリ消費タイミングをずらそうとしていました。
import sqlalchemy # noqa
起動時
次のように重たいライブラリを先に読み込んでおくことで対応しようとしていました。しかし、起動時にメモリ消費が多いのに、読み込むタイミングをずらしても意味はほとんどありませんでした。
lifespan時
FastAPIではアプリケーション起動後からリクエスト受信前に一度だけ実行されるロジックを記載できます。このタイミングでライブラリを読み込むことは一定の効果を得られました。ただし、一定といってもかなりごくわずかだったので意味が薄かったです。
ヘルスチェック時
ECSではヘルスチェックが通って問題ないときに旧アプリと新アプリを入れ替えるような設定を入れていました。そのため、ヘルスチェックのエンドポイントでライブラリを読み込むようにしました。ただ、このタイミングで読み込んでも起動時のメモリが消費されたままであることが多く、import timeには大きい影響を与えませんでした。
エンドポイントアクセス時
エンドポイントにアクセスされたタイミングでimportすることで、メモリ消費タイミングをずらそうとしました。
これもメモリに対しては一定の効果を得られたのですが、アプリケーションの挙動を安定させることができず断念しました。
唯一効果があった処理
ファイルの上部でimportするとファイルを読み込んだタイミングでライブラリを読み込んでしまうため、メソッド内でimport処理をしました。かなり重めな機械学習のライブラリをメソッド内に入れることで、メソッド実行時にライブラリが読み込まれるため改善が見込めました。ただ、多用するとソースコードの見通しも悪くなるため、部分的に適用したものの、基本的には対応していないです。
# メソッド内でimportする例(効果的な方法) def process_data(): # 重いライブラリはここでimportする import google.generativeai
学んだこと
アプリケーション起動時には、次のことを意識すると起動時のメモリ消費量を減らせます。
- APIのroutingのファイルは最低限のファイルしか読み込ませない
- routingの以外の処理はすべて別ファイルに追い出し、メソッド内で読み込ませる
ソースコード
なし
終わりに
最終的には何もできていないのですが、いろいろと学べました。あとでこういう問題に当たらないように、最初から意識して設計するべきですが、手遅れになってから気づくのでなかなか難しいですね…。