LAPRAS SCOREをPythonで取得し、GitHub ActionsでGitHub Profileを更新する
私は自分の力を客観的に判断するために、LAPRAS様を利用しています。LAPRAS様でLAPRAS SCOREなるエンジニアの能力を数値化したものがあり、そちらを利用してGitHub Profileに貼り付けていましたが、自分でキャプチャして画像化したものなので一定期間更新していないと情報が古くなってしまいます。
LAPRASのプロフィールリンクを踏んでもらえれば画像化する必要はないものの、わざわざアクセスしてくれる人は少ないので画像としてアピールしたかったです。
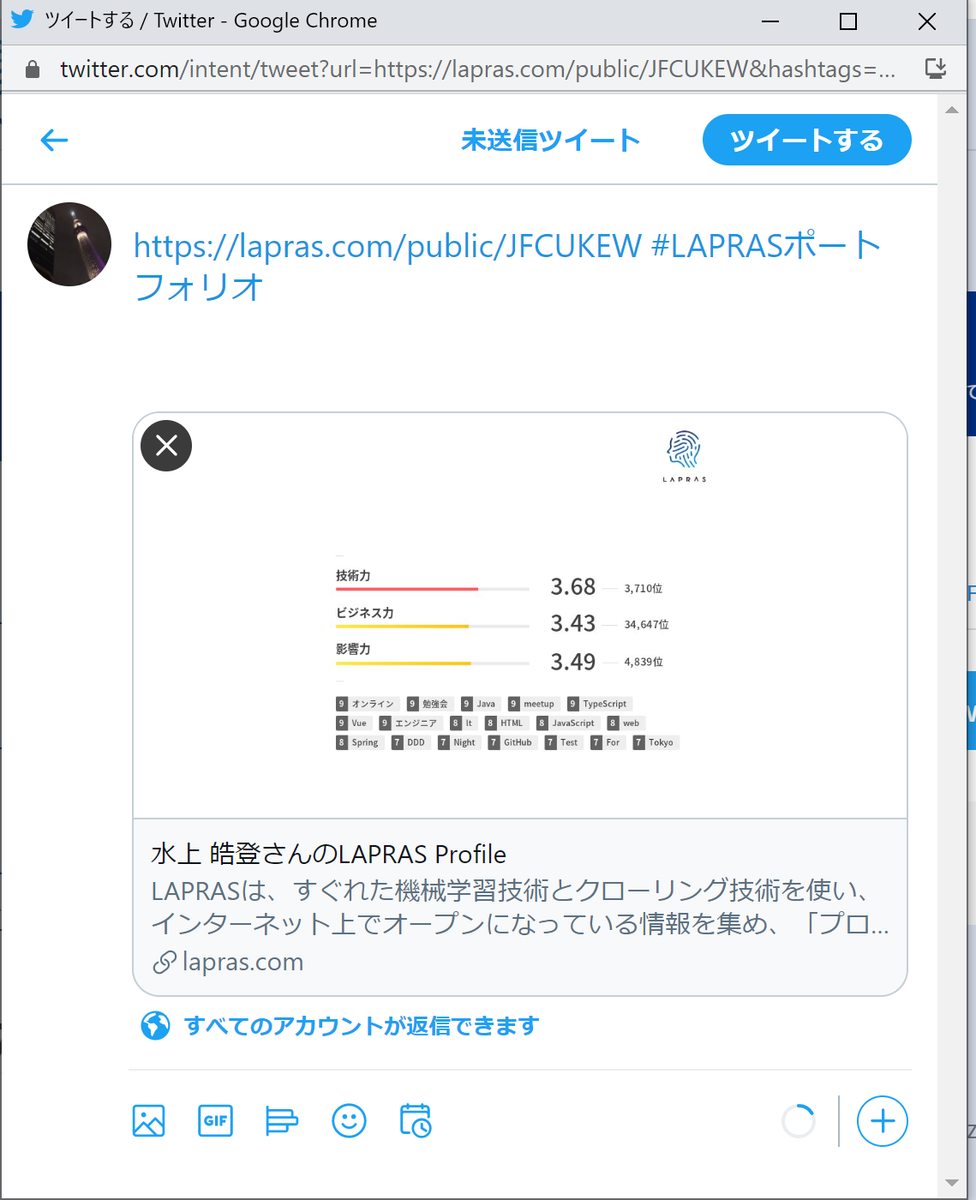
なんとか画像化を自動化しようとしていたところ、LAPRAS様の公開リンクでTwitter共有するとOGP画像で、目的の画像が出力されていることに気付きました。
そこでLAPRAS様のOGP画像を利用し、そのままGitHub Profileへの更新を自動化するための記録を残しているのが、この記事となります。
※OGP画像とは。
SNS投稿した際に表示される画像のこと。
言葉の定義
LAPRAS SCORE
転職サイトのLAPRAS様が出しているエンジニアとしての能力を数値化したもの。

GitHub Profile
GitHubのプロフィールページのこと。
私の場合は、次のリンク先のページが該当します。
hirotoKirimaru (kirimaru) · GitHub
ゴール
- LAPRAS SCORE画像のリンクを取得するアプリケーションを作る
- GitHub Profileに記載しているLAPRAS SCORE画像のリンクを更新する
- GitHub Actionsで実行できるようにする
書かないこと
- GitHub Profileの作り方
環境
- アプリケーション
- Python 3.9
- Pipenv
- Beautifulsoup4
- 取得したHTMLを加工する
- Requests
- HTTP通信を行う
- CI
- GitHub Actions
- GitHub
- GitHub Profile
アプリケーション編
初期構築を行う
Pythonの環境構築をします。
pipenv --python 3.9 pipenv install requests pipenv install beautifulsoup4
置換用の文言を入力します。アプリケーションを実行したらすぐに書き換えるので、リンクは適当でもいいですが、必ず何かを入力してださい。
ファイル名:path.txt
https://media.lapras.com/media/public_setting/XXXXXXXX.png
ファイル名:README.MD

Pipfileに実行スクリプトを書く
Pipenvの起動スクリプトを記載します。
[scripts] start = "python main.py"
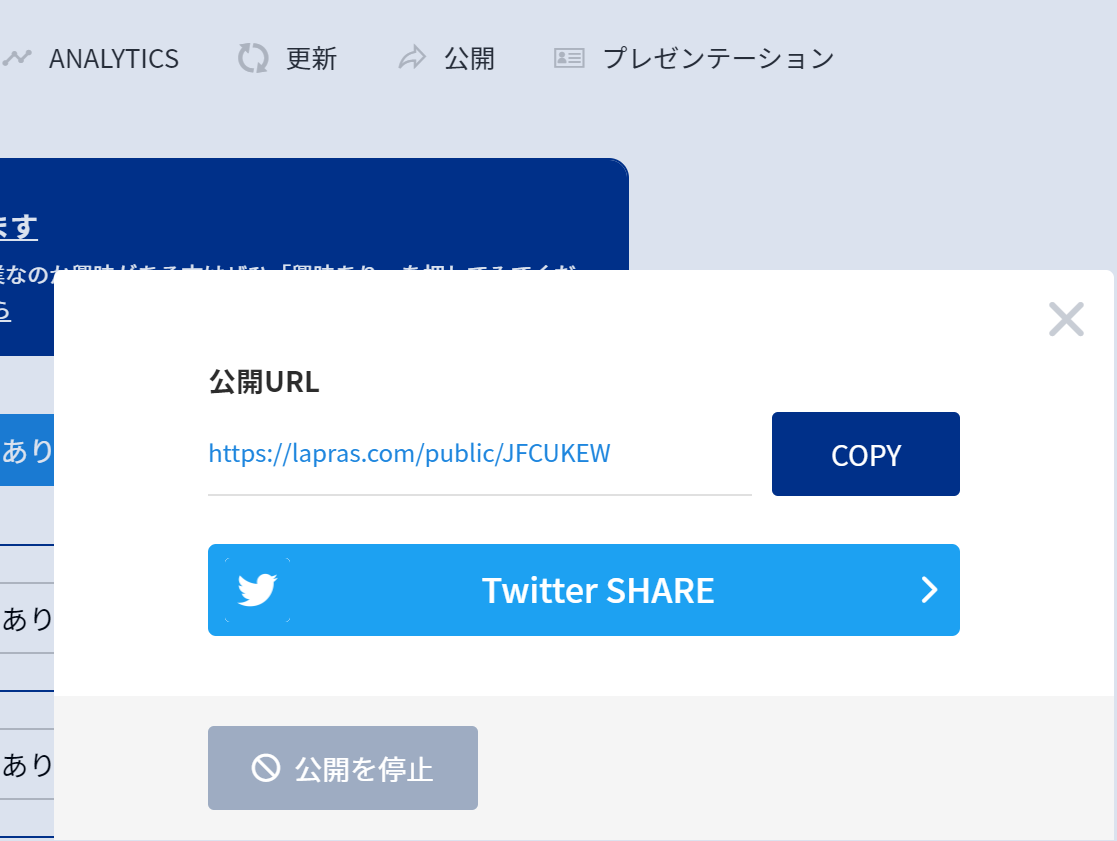
LAPRASの公開URLを取得する
LAPRASの公開URLをWebページから取得します。
公開URLから画像リンクを取得する
上で取得した公開URLにHTTP通信を行うと、TwitterのOGP画像が取得できます。
metaタグのnameが「twitter:image」のcontentが目的の画像リンクです。
<meta name="twitter:image" content="https://media.lapras.com/media/public_setting/JFCUKEW/6b2122adc53449dcb4c69a33d5364954.png" />
main.pyにロジックを書いていきます。
HTTP通信を行うためのrequestsと、HTML構造を取得するためのBeautifulSoupをimportします。
requests.getに上で取得した公開ページのリンクを渡します。
その後、取得できたHTMLからmetaタグのみを取得します。
metaタグのcontentに「https://media.lapras.com/media/public_setting」を含んでいれば画像のリンクとみなします。
※ 本当はmetaタグのnameで検索したかったのでが、BeautifulSoupの仕様でnameは検索できないようでした。
import requests from bs4 import BeautifulSoup # Webページを取得して解析する # 自分のURLを入力する load_url = "https://lapras.com/public/JFCUKEW" html = requests.get(load_url) soup = BeautifulSoup(html.content, "html.parser") content = "" for tag in soup.find_all(name = "meta"): content = tag['content'] if "https://media.lapras.com/media/public_setting" in content: break
画像リンクが前回と同一だった場合は更新しない
GitHubのコミットを最小限にしたいので、リンクが前回と同一だった場合は更新しないようにします。
import sys read = "" with open("path.txt", "r") as path: read = path.read() if read in content: sys.exit()
以降の処理は、リンクが前回と異なっている前提です。
GitHub Profile(README.MD)を更新する
GitHub Profile(README.MD)に記載していた画像のリンクを、新しいものに書き換えます。同様のタイミングで、path.txtに記載していた画像リンクを更新します。
after = "" with open("README.md", "r") as readme: after = readme.read().replace(read, content) with open("README.md", "w") as readme: readme.write(after) with open("path.txt", "w") as path: path.write(content)
GitにPushする
シェルでGitにPushします。特に大事なのはemailとnameです。無ければGitHub Actionsで更新できません。
git config --local user.email 'GitHubのメールアドレス' git config --local user.name '更新用のユーザ'
import os os.system("git config --local user.email 'GitHubのメールアドレス''") os.system("git config --local user.name '更新用のユーザ'") os.system("git add .") os.system("git commit -m '[Auto] Update'") os.system("git push")
GitHub Actions編
こちらはPipenvが実行できればいいので、難しいことはしていません。
手動実行や、スケジュールを指定して定期実行できるような仕組みにしているといいでしょう。
name: Python application on: workflow_dispatch: # 手動実行用 branches: [ master ] push: branches: [ master ] pull_request: branches: [ master ] jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Set up Python 3.9 uses: actions/setup-python@v2 with: python-version: 3.9 - name: Install Pipenv run: | python -m pip install --upgrade pip pip install pipenv - name: Install dependencies run: | pipenv sync - name: update run: | pipenv run start
ソースコード
終わりに
HTML構造を取得するスクリプトを素振りしたかったので、いい機会でした。
今回取得したいLAPRAS SCOREはあくまでLAPRASのOGP画像に左右されるので、生成タイミングによっては最新の成績と一致しないことありますが、可能な限り最新な状態で維持できるでしょう。
自分のように、最新のLAPRAS SCOREを取得したい、かつCIで自動化したいという人の参考になれば幸いです。
この記事がお役に立ちましたら、各種SNSでのシェアや、今後も情報発信しますのでフォローよろしくお願いします。
参考
Beautiful Soupのリファレンス https://www.crummy.com/software/BeautifulSoup/bs4/doc/#
