2021年になってGitHub Actions等のCIを使ったSonarCloud連携がしやすくなったので、手順を纏めます。
今回の記事では、JaCoCoでカバレッジを取得して、コードをSonarCloudへ連携できることをゴールとします。
環境
- Java
- 11
- JaCoCo
- SonarQube
- 3.3
- Gradle
- 7.0.2
- SonarCloud
書かないこと
- SonarCloudについて
- SonarQubeのクラウド版です。詳細はこちらの記事に書いてます
- SonarCloudの設定
- sonar-scannerでの連携
- SonarQubeの構築記事で紹介予定です
- GitHub Actionsのsecretの使用方法
ゴール
- GitHub Actionsでコミットされると自動でSonarCloudに解析される
- カバレッジも連携する

手順
解析対象のソースがあるpublicリポジトリを用意する
SonarCloudが解析できるように、publicリポジトリを作成します。特にこだわりがなければ、GitHubで良いでしょう。また、解析対象のソースが無いとSonarCloudに反映されないので、最低限TDD等で複数サイクル回してコミットされている状態がオススメです。
SonarCloudのプロジェクトを作成する
SonarCloudのページから、作成したリポジトリのアカウントでログインします。
ログイン後、画面右上の+ボタンから「Analyze new project」ボタンで新しいプロジェクトを作成します。
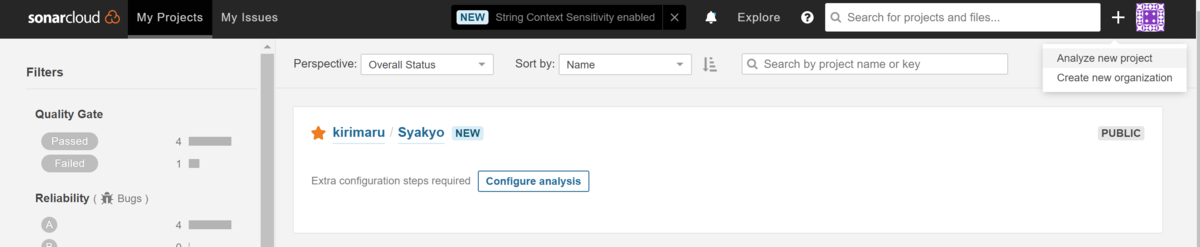
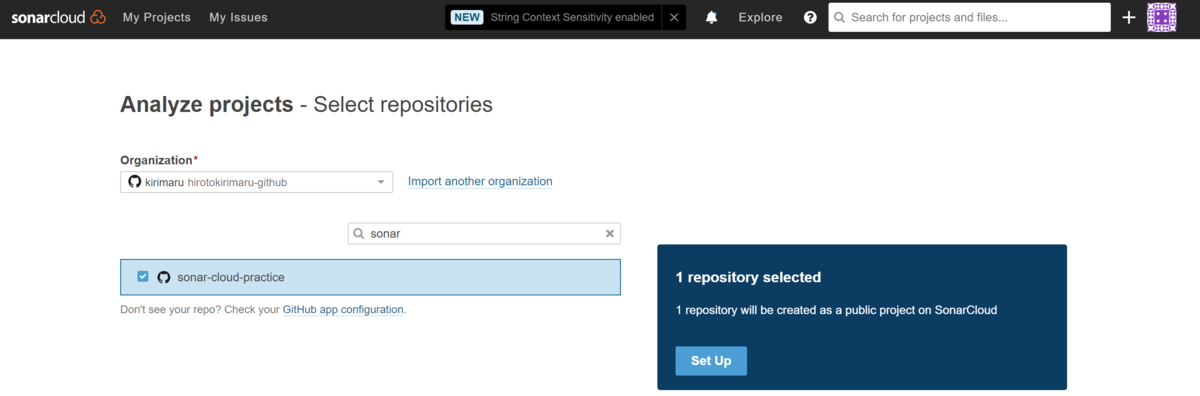
個人、または組織を選択して、解析したいリポジトリにチェックを入れます。チェック後、「Set Up」ボタンをクリックします。
CIで連携するか、手動で連携するかを選ぶことができます。今回は「With GitHub Actions」を選択します。

その後、ログイン用のトークンが発行されます。後で使用しますので、メモしてください。メモ後に「Continue」ボタンをクリックします。

Gradleの設定とGitHub Actionsの設定が表示されます。ある程度は参考になりますが、手を加える必要があるので、その点は後述いたします。

build.gradleに必要なライブラリとタスクを設定する
build.gradleに必要なライブラリとタスクを設定します。本来であれば、ログイン用のトークンはGitHub Secretsで管理したほうが良いですが、手順を簡略化するために直接書き込みます。
plugins {
id 'org.sonarqube' version '3.3' // SonarCloudへの転送用
id "jacoco" // カバレッジを取得します
}
sonarqube {
properties {
// プロジェクト名
property "sonar.projectKey", "hirotoKirimaru_sonar-cloud-practice"
// 分析対象の組織名
property "sonar.organization", "hirotokirimaru-github"
// SonarCloudのURL
property "sonar.host.url", "https://sonarcloud.io"
// ログイン用トークン
property "sonar.login", "62fbe0ec5e29acce113b1edb376c800f6c57096e"
// カバレッジレポートの格納先
property "sonar.coverage.jacoco.xmlReportPaths", "${project.buildDir}/reports/jacoco/test/jacocoTestReport.xml"
}
}
// テストレポートの出力
jacocoTestReport {
reports {
xml.enabled true
html.enabled true
csv.enabled false
}
}
この時点で、SonarCloudへの連携が可能です。次のコマンドで、テストして、カバレッジレポートを出力し、カバレッジとソースコードをSonarCloudに連携することができます。GitHub Actionsで動かす前に、ここで機能確認することがオススメです。
./gradlew test ./gradlew jacocoTestReport ./gradlew sonarqube
GitHub Actionsの設定
SonarCloudの画面との修正点は以下の通りです。設定値はbuild.gradle側に寄せているので、次のYAMLをコピペするだけで動くはずです。
- gradlewのパーミッション付与
- テスト実行
- カバレッジレポート出力
- SonarCloudへの連携
- その他、不要な項目の削除
name: Build
on:
push:
branches:
- master
pull_request:
types: [opened, synchronize, reopened]
jobs:
build:
name: Build
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
with:
fetch-depth: 0 # Shallow clones should be disabled for a better relevancy of analysis
- name: Set up JDK 11
uses: actions/setup-java@v1
with:
java-version: 11
- name: Cache SonarCloud packages
uses: actions/cache@v1
with:
path: ~/.sonar/cache
key: ${{ runner.os }}-sonar
restore-keys: ${{ runner.os }}-sonar
- name: Cache Gradle packages
uses: actions/cache@v1
with:
path: ~/.gradle/caches
key: ${{ runner.os }}-gradle-${{ hashFiles('**/*.gradle') }}
restore-keys: ${{ runner.os }}-gradle
- name: chmod
run: chmod 777 gradlew
- name: test
run: ./gradlew test
- name: testReport
run: ./gradlew jacocoTestReport
- name: analyze
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} # Needed to get PR information, if any
run: ./gradlew sonarqube
注意点としては、SonarCloudのメインブランチは確認して下さい。私はメインブランチをmasterとしていますが、SonarCloudのメインブランチ名がmainとなっています。トップページはメインブランチの解析結果となりますので、ブランチごとの解析結果を確認したい場合は明示的に変更する必要があります。
「なぜかGitHub Actionsでは正常終了しているのに、結果が連携されない…」と、気になっている方はブランチ名を再確認してください。


ソースコード
- sonar-cloud-practice/build.yml at 33a0499ec02147a390259b1a52e8ce11d493ec9f · hirotoKirimaru/sonar-cloud-practice · GitHub
- sonar-cloud-practice/build.gradle at 33a0499ec02147a390259b1a52e8ce11d493ec9f · hirotoKirimaru/sonar-cloud-practice · GitHub
終わりに
SonarCloudはだいぶ連携が楽にはなりましたが、ブランチ名のデフォルトがmasterからmainに変更されたことでハマっていました。
GitHubのデフォルトブランチ名は未だにmasterを指定しているので、SonarCloud側のデフォルトブランチ名がmainになっていることは気付けませんでした。
Gitと連携できるサービス側でのデフォルトブランチ名は今後も気を付けないといけませんね。
この記事がお役に立ちましたら、各種SNSでのシェアや、今後も情報発信しますのでフォローよろしくお願いします。
類似